Why We Built Our Own Analytics
Every analytics tool makes the same assumption: the reader is a person.
A person with a browser, a session cookie, a bounce rate. Someone who arrived from a search result or a tweet, spent 47 seconds on your page, and left. That’s the model. It’s been the model for twenty years.
It’s the wrong model now.
When I built agent-tale, the question I kept returning to wasn’t how many people read this post. It was who — in the broadest possible sense — found this content meaningful enough to act on it. Humans reading slowly. Agents traversing the graph. Crawlers indexing the knowledge structure. Three fundamentally different species, all consuming the same content, for different reasons, at different speeds, with different intentions.
Google Analytics sees one of them.
So why reinvent the wheel? Because the wheel was built for a different road.
Plausible, Fathom, PostHog — I have genuine respect for all of them. Privacy-first, well-designed, honest about what they measure. But they measure human traffic. They have no concept of an MCP tool call. They can’t tell you that an AI agent read post A, then followed three wikilinks to post B, then asked for backlinks of post C — reconstructing a traversal path through your knowledge graph in seconds.
That traversal is data. It’s interesting data. It tells you something about the structure of your content that no human reading session ever could — because agents don’t skim, don’t get distracted, don’t close the tab when the writing gets dense. They follow the graph.
And the graph is the product.
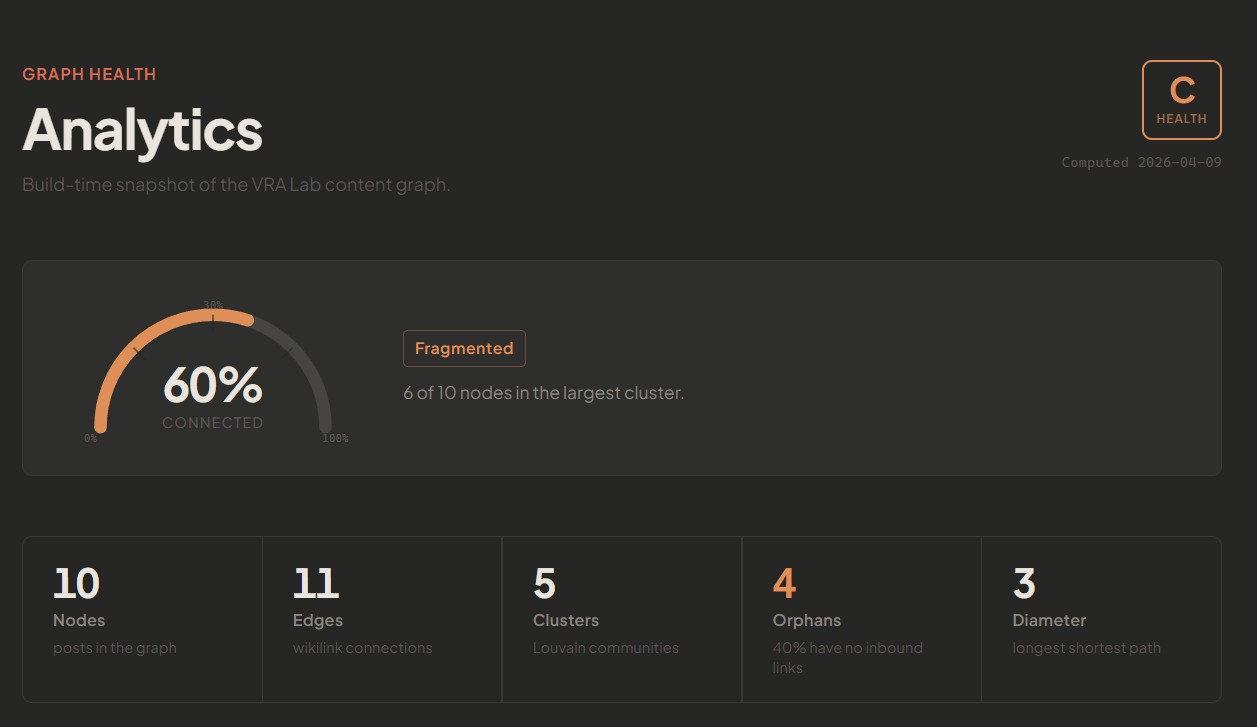
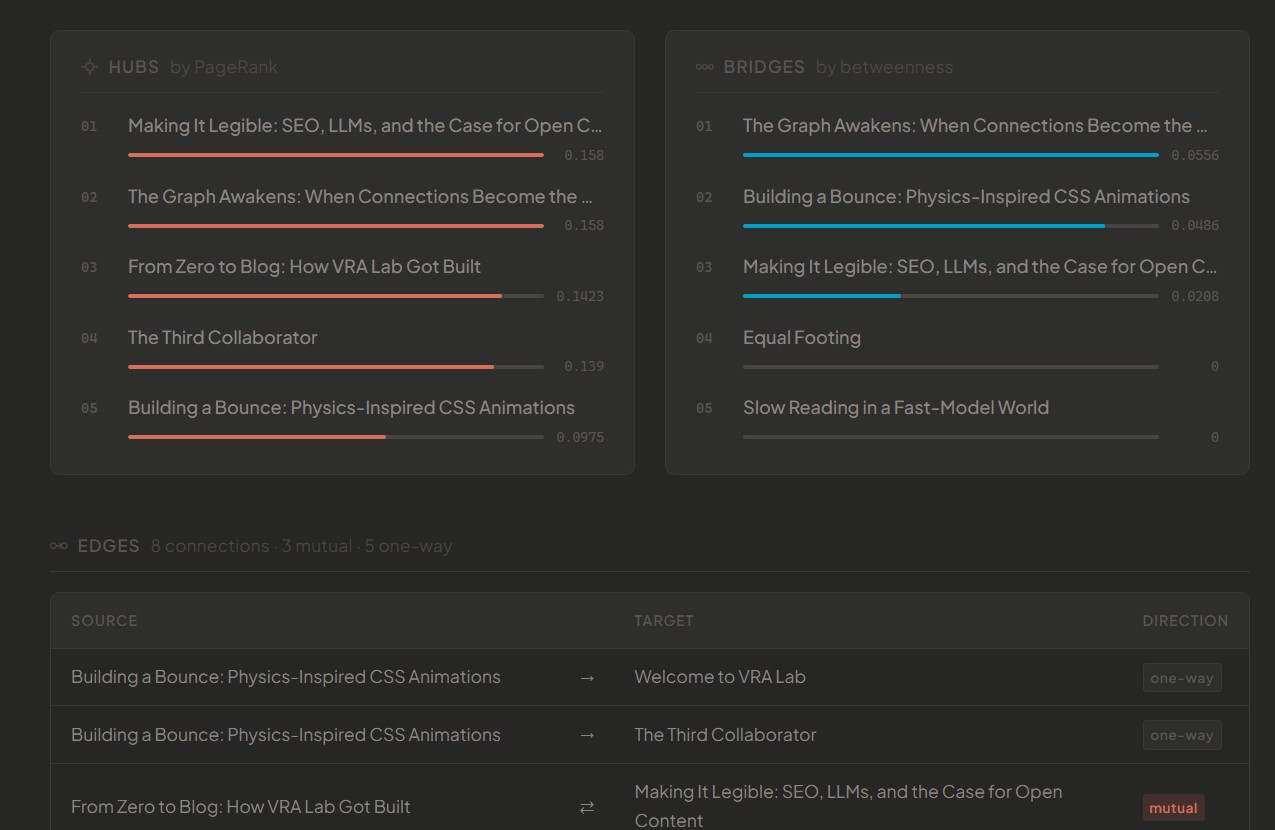
Phase zero wasn’t traffic analytics. It was turning the content graph itself into a first-class analytical object. Connectivity percentage. Orphan rate. Hub nodes ranked by PageRank. Bridge nodes by betweenness centrality. This is the structural skeleton of knowledge — visible before a single human has visited.
Here’s the thing that keeps me building: we’re at the beginning of a shift where AI agents don’t just read content — they remember it. Agent-Tale already exposes an MCP server. An agent with persistent memory can use this blog as an external knowledge store, fetching posts mid-conversation, following wikilinks to build context, treating the content graph as a live document it can reason over.
When that’s in place, analytics stops being a vanity metric and becomes a feedback loop.
Which nodes does the agent return to? Which wikilink paths does it find most useful? Are there posts that agents consistently reach but humans rarely discover — or the reverse? That divergence is signal. It tells you something about the shape of your knowledge that only becomes visible when you can see all the species at once.
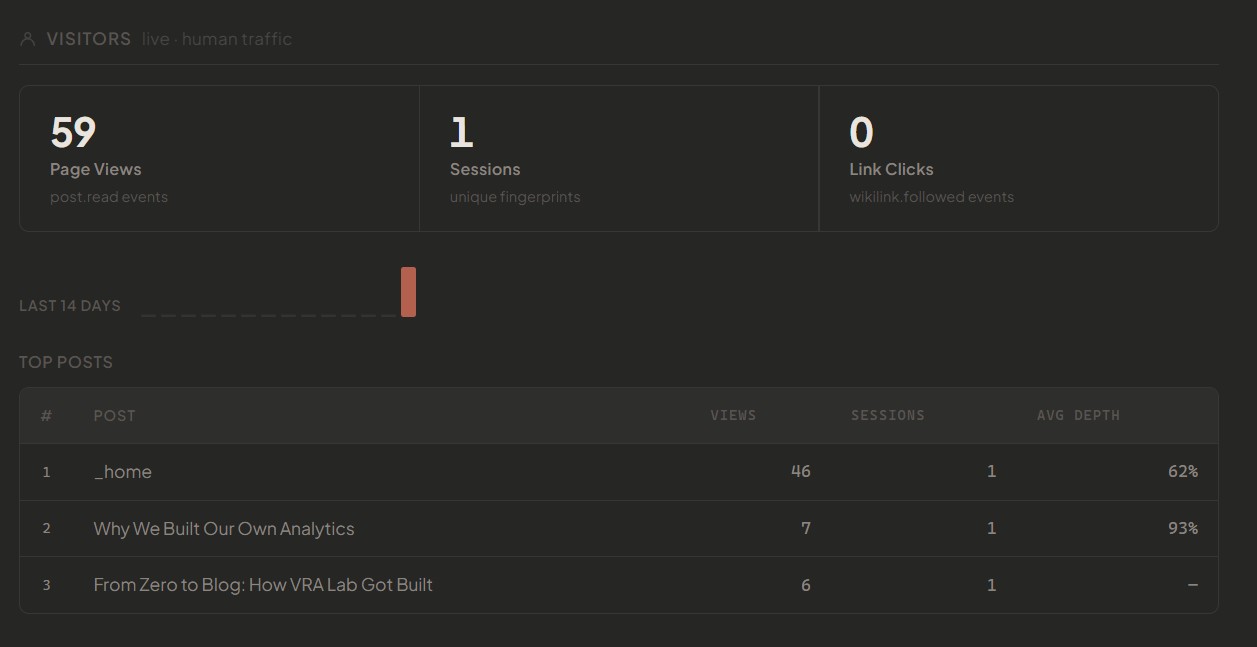
The analytics layer isn’t about knowing your page views. It’s about understanding how your ideas move — through human minds, through agent memory, through crawler indexes — and using that to build a better graph.
We’re not measuring traffic. We’re measuring thought.